Written for Knowledge Exchange by Andrea Chiarelli (Research Consulting)
Arxiv, the most widely known preprint server, has received over 1.5 million preprints since its inception in 1991. BioRxiv, a growing equivalent in the life sciences that was started in 2013, hosts over 40,000 submissions representing the work of over 160,000 researchers from more than 100 countries. It is undeniable that preprints are a growing force in the scholarly communication landscape but what does their future look like?
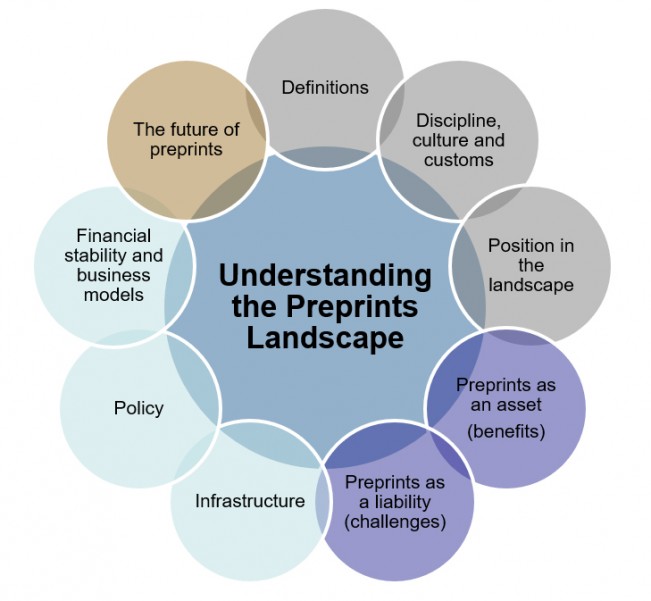
Knowledge Exchange has been investigating this fast-changing and exciting landscape since 2018 and asked Research Consulting to conduct a study on the status and impact of preprints. KE has recently released a slide deck summarising the results of the first stage of the work. This involved an initial literature review, followed by 38 interviews with research funders, research performing organisations, preprint servers, other service providers and researchers. In this post, I will take you through some of the key findings and will highlight what will happen next. For the purposes of the present discussion, the term preprint is used to describe the following:
______
A version of a research paper, typically prior to peer review and publication in a journal.
______
The first preprint I wrote was 50 years ago. When I wrote my first paper, it was typed out carbon copies and sent to people who might be interested.
Researcher
Where it all began
Physicists at Los Alamos National Laboratory startedarXiv in 1991 and the electronic dissemination of economics working papers(their own flavour of preprints) can be traced back to 1993, when the Working Papers in Economics (WoPEc) project started.
Clearly, preprints are not breaking news: they have been around for half a century, starting in the form of carbon copies, but it's only over the last 20 years that they have become a disruptive force. Their significant growth has been underpinned by technological developments and, particularly, by the broad diffusion of online databases and repositories. While these almost always had to be built ad-hoc in the past, today it has become relatively easy to get an online database up and running.
The example set by the maths, physics and economics communities is now being picked up by a range of other disciplines and the ease of sharing content online has been a key enabler of this development. BioRxiv (launched in 2013), PsyArXiv (2016) and ChemRxiv (2017) were the starting point of this study, but a very wide range of preprint servers are now available, with new ones being set up every year using a range of technical solutions.Interestingly, we found that the discussion around the value of preprints appears to be re-starting in each discipline, as the merits of this newly-blossoming approach to knowledge dissemination depend on disciplinary customs and existing approaches to information sharing.
Someone might tweet that they've just published something, and I'll click through and it's a preprint I won't necessarily be looking for preprints, but I get exposed to them much more via Twitter.
Researcher
The enabling power of social media
An unexpected yet eye-opening finding of this research is the extent to which Twitter has been enabling the uptake of preprints in many disciplines. While Twitter is an open and publicly-available medium by nature, "closed" scientific communities are using it to discuss their work, latest findings and trends. Particularly, Twitter allows users to:
- discover preprints posted by peers;
- follow Twitter bots posting preprints from specific servers;
- share their own preprints;
- make and receive comments; and
- promote their work and contact editors of high-impact journals when social media attention is high.
Without Twitter, many of our study participants wouldn't even have known about preprints in the first place. We heard relatively often that people had never heard about preprints until a peer tweeted about one: this typically led to interested researchers digging into the concept and finding our more.
Who is in charge when it comes to preprints…
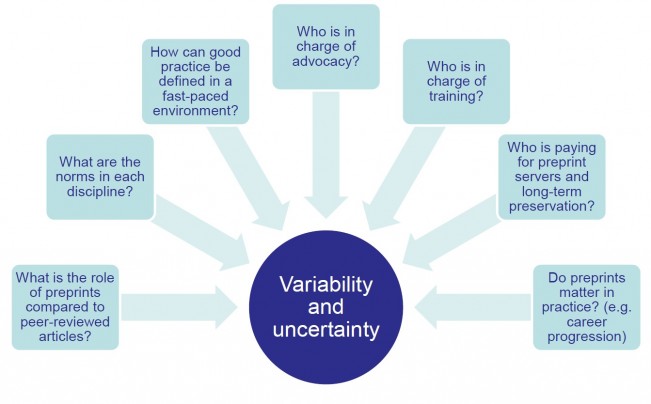
Over the course of the research, we came to realise that the preprints landscape is characterised by significant variability and uncertainty. There are numerous open questions (see Figure 1),which do not all have answers at present: these include roles and responsibilities in terms of advocacy, training and support, the effect(s) of preprints on career progression and the relationship with peer-reviewed journal articles. Just looking at these examples, the multi-stakeholder nature of the preprints landscape appears clear.
To complicate matters, a number of players and initiatives orbit around preprints and preprint servers. Most notably, we would like to mention overlay journals (e.g. Peer Community in, preLights), preprint journal clubs (e.g. using PREreview) and the technical infrastructure enabling preprints to be indexed effectively (e.g. Crossref, Web of Science).
But the most pressing question is perhaps who is responsible for posting preprints?While all other matters may be resolved via consultations, discussions and further developments in the scholarly communication landscape, this question is of a deeper nature:
- A researcher-centric view, where researchers post preprints themselves, would promote openness and freedom of choice, including independence from academic publishers in an increasingly consolidated publishing market.
- A publisher-centric view would likely lead to smoother workflows and more consistency in terms of preprint posting, e.g. a publisher could post preprints for all articles submitted compared to some authors only doing so themselves.
Today, in most cases, preprints are posted by individual researchers within engaged disciplinary communities. Furthermore, preprint servers are experimenting with technology, workflows and more, which suggests that a publisher-centric view is not yet in sight due to the high level of uncertainty in the landscape. Some solutions such as F1000 Research and PeerJ have, to date, included preprints within their publishing workflows, but the extent to which this might spread more widely is unclear.
Whatever the approach chosen, a key area where clarifications or atleast improved messaging are required is whether preprint posting prior to submission to a journal might lead to articles being rejected for peer-review. Preprint posting is accepted by many journals and information on the topic is often made available by publishers and on Wikipedia (which also highlights publishers who will not accept the practice). However, we found that authors remain wary in some cases.
…and who foots the bill?
In our research, we found that preprint servers are being started and managed via four key approaches as shown in Figure 2 below:
- Some standalone preprint servers, such as bioRxiv and arXiv, have developed their own technical solutions and operate independently of other parties or technological solutions.
- Other standalone preprint servers, such as ChemRxiv, operate using third-party technology and technical infrastructure (in ChemRxiv's case, we note the use of Figshare infrastructure).
- Some publishers, such as PeerJ and F1000 Research, include the posting of preprints as part of publications workflows. Notably, PeerJ also offers the PeerJ Preprints platform, which can be used as a standalone option (i.e. without peer-review).
- Some publishers such as PLOS have started posting preprints of submitted articles to preprint servers (in PLOS's case, preprints are posted to bioRxiv).
Note that, under the two "standalone" headings, we also include services such as Preprints.org and SSRN, which are operated by MDPI and Elsevier, respectively. These are not classified as "publisher-supported" because this label is used to describe preprint posting as part of a more holistic process where posting and peer-review are possible on the same platform.

I think that it is very important that the archive runs as an independent entity and it's not for profit.
Research funder
The choice of model is clearly related to the question of whether the preprints landscape will evolve to be researcher- or publisher-centric. One thing that the participants to our project highlighted was a strong desire for not-for-profit and publisher-neutral models (e.g. via consortia), but we note that the viability of this approach will largely depend on the availability of funding from other sources.
The future of preprints
Going back to the title of this post and considering our discussion above, it does seem that preprints may be bringing us a step closer to science in real time. However, if they are to become a significant force in a wider range of research fields, three important factors should be considered, i.e.
- how preprints can be included in existing scholarly/publishing workflows;
- whether and to what extent preprints should be preserved in the long term;
- whether it may be beneficial and financially feasible to prepare machine-readable xml versions of preprints.
The above factors are complemented by a purely financial consideration: what is the opportunity cost of preprints and preprint servers? This amounts to considering whether the money spent on preprintsand preprint servers may yield better outcomes if invested elsewhere or on other open science or open access initiatives. For example, preprint servers are starting to consider long-term preservation solutions and workflows: if the final version of a preprint has been published as an open access article, is there a practical reason for preserving the former?
The above-mentioned collaboration between PLOS and bioRxiv also begs the question of whether more publishers could be submitting the articles journals receive for review to preprint severs by default. The answer to this would likely depend on disciplinary customs and the potential advantages that the various stakeholders involved would see.
Our five take-aways on preprints
- Twitter is playing a key enabling role in the diffusion of preprints. Even though preprints are nothing new, technology is enabling new ways to leverage this growing approach to scholarly communication. Today, people are often exposed to preprints thanks to Twitter, which is also useful for their discovery and to provide feedback to authors.
- A one-size-fits-all solution that works for all disciplines is not likely to be achievable at present: preprints exist in a complex environment, due to the wide range of technical approaches, business models, roles and responsibilities, disciplinary customs and more.
- Who should be responsible for posting preprints researchers or publishers? This question hints at the models underpinning preprint servers, as these are usually either standalone (e.g. not-for-profit, grant-funded) or publisher-backed. Standalone preprint servers would tend to rely on researchers posting preprints themselves (i.e. they require a high level of engagement), while a publisher-centric approach simplifies workflows but feeds into the concerns around market consolidation in the academic publishing landscape.
- Some researchers are worried that journals may reject their submissions if a preprint has been posted previously: this is a key obstacle to the uptake of preprint servers. Information is often available on publisher websites and on Wikipedia, but the concern remains widespread in practice.
- Suitable business models will have to be developed if preprints are to succeed in the long term. In this process, it will be important to assess the opportunity cost of preprint servers and all related workflows (including long-term preservation): could the same funds be spent differently and have a better impact on open science and scholarly communication?
Continuing our research
The findings of this research were presented at the Open Repositories Conference (Hamburg) on June 12th. We engaged the audience and discussed their key concerns and observations. Knowledge Exchange also presented a poster at the LIBER conference in Dublin and aimed to feed community feedback into a report summarising our findings and implications for different audiences. Knowledge Exchange expects the final report to be released in the autumn and aims to discuss it at relevant conferences such as COASP and FORCE19.
In parallel to this, we published a peer-reviewed article 'Preprints and Scholarly Communication: Adoption, Practices, Drivers and Barriers' with a deeper analysis of our findings, as well as an overview of the way we analysed the results of our research.
Should you wish to comment on our findings, please send an email to Karin van Grieken of Knowledge Exchange at Karin.vanGrieken@surfmarket.nl or you can email me at andrea@research-consulting.com and we'll take it from there.
You can find more about Knowledge Exchange's work on preprints here.